
阿里巴巴 EMO 模型:照片生成逼真的唱歌和說話視頻

阿里巴巴 EMO 模型:照片生成逼真的唱歌和說話視頻
阿里巴巴最近推出 EMO 模型,全稱為「Emote Portrait Alive」。該模型使用深度學習技術分析照片和音訊中的資訊,可根據一張照片和一段聲音音訊 (說話或唱歌) 生成逼真的的說話或唱歌影片。例如,當人物說話時,他們的嘴巴會隨著語音而動。當人物唱歌時,他們的嘴巴和表情會隨著歌詞而變化。
相比現時的圖片轉為影片技術,EMO 模型可算是又一躍進,已不再局限於聲音驅動嘴唇,而是可以根據語言的強度和內容改變照片中人物的表情。
▋【阿里巴巴 EMO 模型教學視頻】圖片 + 聲音,影片人物更逼真,表情更豐富!
EMO 模型如何運作?
EMO 模型使用人工智能 (AI) 分析照片和音訊,人物的嘴型、表情和頸部動作會與音頻內容同步變化。EMO 模型的工作過程主要分為兩個階段:
第一階段
特徵提取:EMO 模型會從照片和音訊中提取關鍵特徵,例如人臉形狀、表情、膚色、語音、語調和音量等。
第二階段
影片生成:在擴散過程階段,預先訓練的音訊編碼器處理音訊嵌入。臉部區域掩模與多幀雜訊整合以控制臉部影像的生成,然後使用主幹網路來促進去雜訊操作。
在主幹網路中,應用了兩種形式的注意力機制:參考注意力和音訊注意力。影片中的人物會隨著音訊的變化而做出相應的表情和動作,例如開口閉合、微笑皺眉等,讓影片更加生動自然。
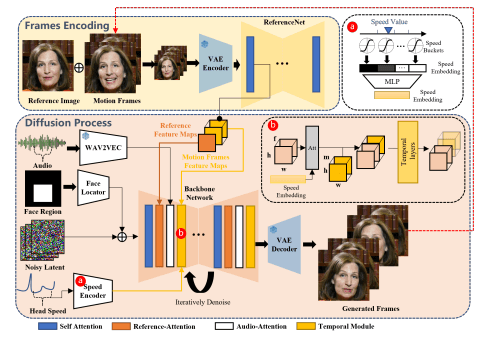
圖片來源: 阿里巴巴 EMO 模型論文
EMO 模型如何訓練?
EMO 模型收集超過 250 小時的鏡頭和超過 1.5 億張影像進行訓練,包括演講、電影、電視節目、歌唱表演,涵蓋多種語言,如中文和英文。照片和音訊用於提取特徵,影片用於評估模型的生成效果。
EMO 模型的訓練過程分為三個階段:
圖像預訓練:
在第一階段,模型會在包含大量照片和音訊的大型資料集上進行預訓練,學習基本的特徵提取能力。
微調:
在第二階段,針對特定應用場景,模型會在包含相關照片、音訊和影片的資料集上進行微調,使其更擅長處理特定類型的內容。
評估:
在第三階段,模型會在與訓練資料不同的測試資料集上進行評估,這個資料集包含與目標應用場景不同的照片、音訊和影片,確保其泛化能力和生成影片的質量。
通過以上三個階段的訓練,EMO 模型可生成逼真的說話或唱歌的影片。
EMO 模型應用場景
阿里巴巴 EMO 模型具有廣泛的潛在應用。它可以用於製作教育影片、娛樂影片、虛擬偶像等。
教育影片:
EMO 模型可以用於製作教育影片,讓學生能夠更直觀地學習知識。例如,可以用 EMO 模型製作影片,講解人體的構造和功能。
娛樂影片:
EMO 模型可以用於製作娛樂影片,為觀眾帶來新的視覺體驗。例如,可以用 EMO 模型製作音樂影片,讓歌手在虛擬世界中唱歌跳舞。
藝術作品:
EMO 模型可以用於藝術作品,提升互動性,拉近與觀眾的距離應。例如,可以用 EMO 模型製作影片,讓畫中的人物說話。
VTuber:
EMO 模型可以用於製作虛擬偶像,即使正音不全,圖片 + 音頻,就可以令 VTuber 唱歌。
阿里巴巴 EMO 模型的推出,標誌著人工智能技術在影片製作領域的又一次突破。不過,雖然專案已經上傳到 Github,程式碼還未正式公開。
▋ 阿里巴巴 EMO 模型: emote-portrait-alive-github
▋ 阿里巴巴 EMO 模型論文: emote-portrait-alive-research-paper
阿里巴巴 EMO 模型教學視頻:
▋【阿里巴巴 EMO 模型】圖片 + 聲音,人物更逼真,表情更豐富!
────⋆⋅☆⋅⋆──⋆⋅☆⋅⋆─────
Lazy Kar 精選 AI 工具系列:
────⋆⋅☆⋅⋆──⋆⋅☆⋅⋆─────
延伸閱讀:
==========================
訂閱 👉 Pulse AI 電子報
✅ 快速掌握最新 AI 工具、科技資訊及品牌應用!
✅ 免費訂閱,節省資料搜集時間!
✅ 加快學習如何運用 AI,減低被淘汰機會!
✅ 每周幾分鐘,工作、學習更高效!
==========================






